We’ve been looking forward to this little box for a while and now have one in for testing:
![]()
Stay tuned for a two-part review 🙂
If you’re using a virtual server (whether online or your own physical machine) it can be handy sometimes to check how many CPU cores are available; here are two easy methods of doing this. The first:
nproc
This will return a single number, whether it be 1, 2, 4 or otherwise. For a more detailed look, try:
lscpu
This will usually give a more complex readout, e.g.:
root@server [/]# lscpu
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 1
On-line CPU(s) list: 0
Thread(s) per core: 1
Core(s) per socket: 1
CPU socket(s): 1
NUMA node(s): 1
Vendor ID: GenuineIntel
CPU family: 6
Model: 45
Stepping: 7
CPU MHz: 2000.024
BogoMIPS: 4000.04
Hypervisor vendor: Xen
Virtualization type: para
L1d cache: 32K
L1i cache: 32K
L2 cache: 256K
L3 cache: 15360K
NUMA node0 CPU(s): 0
This one is straight-forward – if you’re used to Debian and are in a CentOS system looking for /var/log/auth.log you’ll find it in:
/var/log/secure
Short and sweet!
If you’ve imported a pool from another system and want to change the name or have just changed your mind, this is actually quite straightforward to do. Run the following (as root):
zpool export [poolname]
As an example, for a pool named tank which we wish to rename notankshere:
zpool export tank
Then run:
zpool import [poolname] [newpoolname]
e.g.:
zpool import tank notankshere
The pool will be imported as “notankshere” instead.

We get asked fairly regularly about resilver rates for ZFS pools – these matter as it impacts on how quickly a vdev with faulty disks can rebuild data onto a fresh disk, as well as how quickly you can swap one disk for another. The longer it takes to rebuild the vdev after a disk has died, the longer your pool is operating with less redundancy – meaning that if you have had one disk fail (raidz1) or two disks fail (raidz2) already then one more failure before it has finished rebuilding will cause the vdev and zpool to fail.
Today we have been tasked with swapping new drives into two 6-disk vdevs, each consisting of a mixture of WD20EARX and WD20EARS drives – Western Digital 2TB green drives. One array contains 8TB of information, the other 5TB. The 5TB array fluctuates around 245MB/s resilver rate, and the 8TB fluctuates around 255MB/s – giving around 6 hours and 9 hours rebuild times respectively.
These figures are what we would consider typical for that size of vdev, given the disks involved. We will post more rebuild rates and add them into a database over time – stay tuned 🙂
We have a new wireless AP in-house for testing:

It’s pretty inexpensive, but does it do what it says on the box? Stay tuned for a review 🙂
If you’re using Ubuntu and seeing the following error in your Samba log:
Failed to retrieve printer list: NT_STATUS_UNSUCCESSFUL
If you are a home user and using samba purely for file sharing from a server or NAS you’re probably not interested in sharing printers through it. If so, you can prevent this error from occurring by adding the following lines to your /etc/samba/smb.conf:
printing = bsd
printcap name = /dev/null
Restart samba:
/etc/init.d/smbd restart
…check your logs:
less /var/log/samba/log.smbd
and the error should now no longer be appearing.
This is an interesting one – if you have the need to monitor your CPU usage individually across cores it’s actually quite easy with the top command. Simply run top and hit “1” – your output will go from:
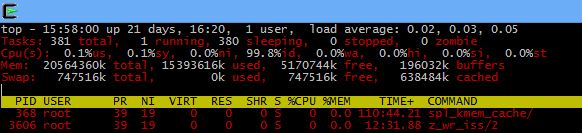
to:
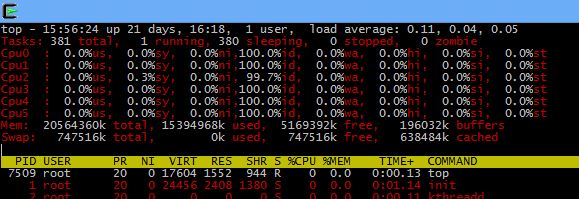
In this case the server is a hexcore (0-5 cores shown, 6 in total) and we can clearly see the loads across each of them. To get colours – it can make top easier to read – hit Z.
This can be quite handy for monitoring your CPU usage in more detail than basic load averages.
Knowing how to limit how long a process will run for is quite useful, particularly when you have daily backup scripts and the like which may at times run more than 24 hours; having multiple processes attempting to synchronize the same files can waste time, bandwidth and CPU power needlessly. The command we will use here is timeout. Ubuntu Server should have this pre-installed. It is used so:
timeout [no. of seconds] [command]
e.g.
timeout 10 rsync /home/user/files/ /backups/user/files/
would run the above rsync command but kill it after 10 seconds.
This can be particularly useful with your daily scripts; simply set the timeout to be a few minutes less than 24 hours and you should hopefully avoid them running over each other. For reference there are 3600 seconds in an hour and 86400 seconds in 24 hours; setting a process to timeout after 86000 seconds would result in it running for 23 hours, 56 minutes and 20 seconds.
If you’re writing scripts or making cron jobs you will need to know the full path of the commands you’re using; rather than just being able to use “ls” you would have to use “/bin/ls” instead. You could use the find command here but there’s a quicker and more elegant way: which. Use it like so:
which ls
will return:
/bin/ls
Not everything will be in /bin, e.g.:
which timeout
will likely return:
/usr/bin/timeout
Simple but it will make your life quite a bit easier when writing scripts, particularly with new commands or command which you don’t use often.